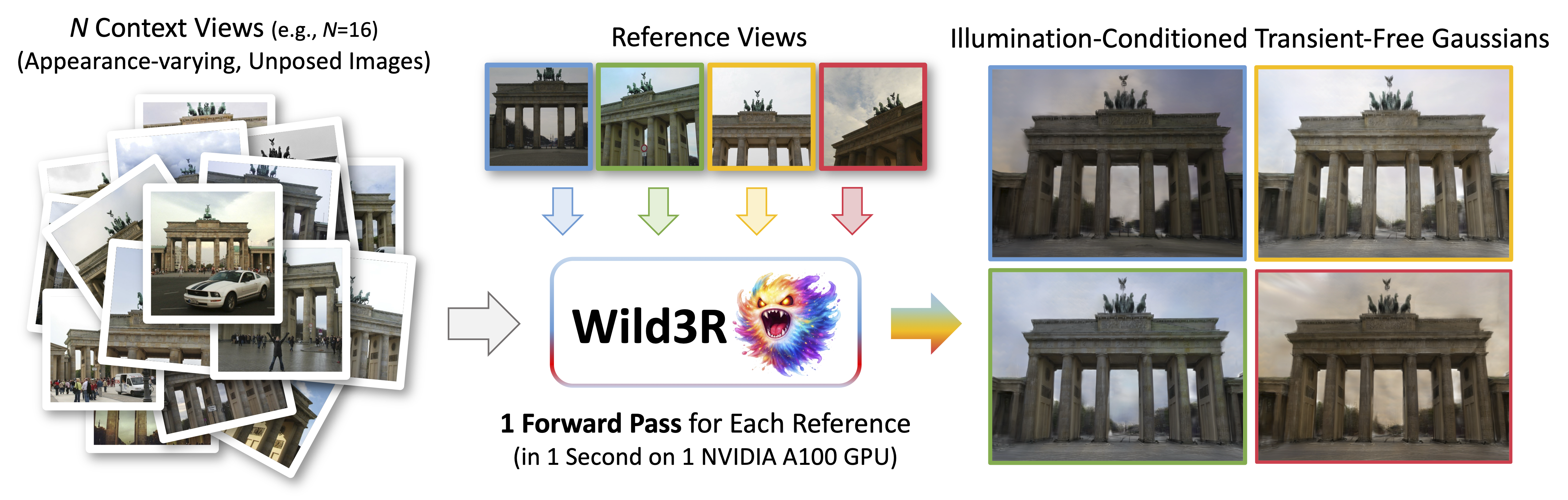
Our WildCity dataset is designed to train feed-forward 3DGS models for 3D reconstruction from unconstrained photo collections. The dataset creation process consists of four main stages.

@article{furutani2026wild3r,
title = {Wild3R: Feed-Forward 3D Gaussian Splatting from Unconstrained Sparse Photo Collection},
author = {Furutani, Yuto and Otonari, Takashi and Shiohara, Kaede and Yamasaki, Toshihiko},
journal = {arXiv preprint arXiv:2606.11894},
year = {2026}
}